Our workflow standardizes the process of implementing deep learning (DL) use cases for electron microscopy
(EM). It is designed for DL experts by streamlining training, testing, and inference through a PyTorch-based
playground with a jupyter notebook based interface for easy use by EM experts.
DL experts can easily contribute their own use cases using our template.
This approach
enables
electron
microscopists to work with a single, user-friendly implementation to get more familiar in the area of deep
learning,
while simplifying the development process for DL
specialists.
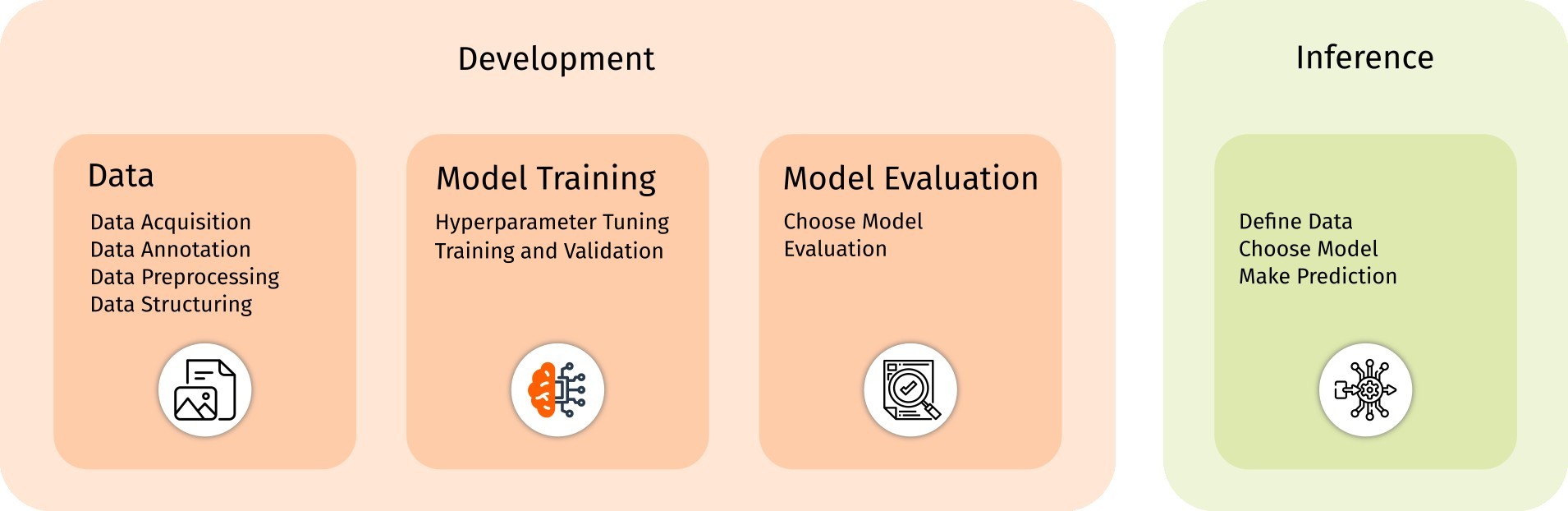
Figure 1: We propose a simple workflow for developing deep learning solutions for the supported analysis of EM
data.
The workflow is designed in such way, that it allows DL experts to implement and provide DL solutions and
evaluation methods with minimal overhead, while EM experts are able to train their own models.
In the following, we will introduce the steps of the workflow to EM specialists as well as DL specialists.
Please open the corresponding tab when reading.
Development
In deep learning for electron microscopy (EM), the process of creating and optimizing models to address
specific challenges within EM is known as development. This process is structured around three key steps:
Data: Preparing high-quality, well-annotated datasets tailored to your lab’s needs.
Model Training: Training models by optimizing architectures and parameters.
Model Evaluation: Evaluating the model’s performance using task-specific metrics.
These steps ensure deep learning models are effectively adapted for EM tasks, providing solutions
specific to your lab's requirements.
1. Data
Data preparation is a critical aspect of the deep learning pipeline. Recognizing that expertise in data
collection and annotation primarily resides within EM labs, our workflow is designed to provide guidance
for EM researchers to develop their own datasets in collaboration with DL experts.
While each use case in our workflow focuses on a primary task (e.g., counting objects in EM images), the
workflow is flexible enough to allow you to swap the application area (e.g., quantifying mitochondria in
EM images) without needing to modify the code—only the data needs to be replaced.
1.1 Data Acquisition
Data acquisition is the first step in creating a dataset. This involves gathering raw EM images,
typically from various imaging modalities such as TEM, STEM, or SEM. As a EM expert, your role is to
collect diverse and well-balanced datasets that cover a range of features
relevant to the task. DL experts will support and guide you through the process if needed by providing
nessecary information within their use case.
1.2 Data Annotation
Annotating EM data is often the most time-consuming part of dataset preparation. Our workflow enables
EM researchers to annotate their data using the Vision
Annotation Tool (CVAT), a user-friendly
tool that simplifies this process.
We provide a step-by-step guide for setting up CVAT and
annotating images.
Each use case provides a step-by-step guide for the needed annotations, in order to allow you as EM
researcher to annotate your own dataset for training a deep learning model.
1.3 Data Preprocessing
Data preprocessing is essential for preparing your dataset for model training. It includes several
important steps:
Data Reformatting: Ensures that your data is compatible with the deep learning
code. We recommend DL experts who contribute their work to be using standard formats such as .tif or
.mrc.
Image Enhancement: Image enhancement involves improving image quality using
techniques such as denoising and contrast adjustment. In some cases, these enhancements can boost the
training and downstream performance of deep learning models. If necessary, the steps to enhance your
data will be documented within each specific use case.
1.4 Data Structuring
Correctly structuring your data allows you to adapt the use case application based on the provided
training data. To do this, you will need to follow the data structure defined by the DL expert.
For simplicity, DL experts are encouraged to organize the dataset into a single folder for training,
validation, and testing when submitting their work to the playground, as data splitting can be handled
during runtime. This approach simplifies the data structuring process for EM experts. Details will be
documented within each use case individually.
2. Model Training
During training, the model learns patterns from
the data by adjusting its internal parameters (weights) based on the input-output relationships. This
process is guided by a loss function, which measures the error between predicted and true values
(labels/annotations). The
model is iteratively updated to minimize this error. Validation, on the other hand, involves evaluating
the
model’s performance on a separate set of data (the validation set) that it hasn't seen during training.
This
helps to check how well the model generalizes to new, unseen data and aids in detecting issues such as
overfitting. The training and validation processes together ensure that the model is well-suited for the
task at hand and can deliver reliable results in real-world applications.
2.1. Hyperparameter Tuning
Hyperparameter tuning is the process of selecting the best values for parameters that influence the
model's performance, but cannot be optimized during training. We offer an automated search to simplify
this process. DL experts define a default search space for those who prefer not to engage with the
technical details. If you are more experienced or willing to learn about the process, we offer the
ability
to
modify the search space as needed without code changes, but by filling a simple form. The DL expert will
provide explanations of the incluence of each tunable parameter within the use case.
2.2. Training and Validation
During model training, performance is continuously monitored through logging. This provides EM
researchers with valuable insights into the training process, helping identify issues like overfitting
or
data biases, and learning about the process of model training.
For each execution of the full notebook , logs are saved in a dedicated directory
(logs/data-current-datetime/).
For each training run a subfolder will be created. There can be multiple folders called
Sweep_idx containing the logs for each sweep run of the hyperparameter tuning.
Additionally, there will be one subfolder TrainingRun containing the logs for the full
model training. Finally, there is one subfolder Evaluate containing logging results of the
evaluation.
Each subfolder may contain following logs:
Model evaluation assesses whether the trained model meets the desired criteria and is ready for
deployment
or requires further refinement.
3.1. Choose Model
Typically, the most recent model is selected for evaluation, but you can also evaluate other models by
providing the checkpoint path.
3.2. Evaluation
To help you assess the models performance, the DL expert determines the specific evaluation metrics
based
on the model's goals. Each used metric will be explained within the use case by the DL expert to provide
a
better understanding of the aspects of evaluation. This can also help to identify possible shortcomings
of
the evaluation by EM experts.
Please note that the DeepEM Playground provides a tool to bridge the gap between DL and EM experts,
fostering improved research in this interdisciplinary field and demonstrating the power of deep
learning.
However, none of the trained models are flawless and should always be used with human oversight. We do
not
take responsibility for any irresponsible usage of the models or their predictions.
Development
In the context of deep learning for electron microscopy (EM), the development phase involves designing
and optimizing models to address specific tasks within EM research. This process is divided into three
key steps:
Data: Ensuring datasets are well-structured and ready for deep learning
tasks, which often requires expert input from EM researchers to curate high-quality, annotated data.
Model Training: Optimizing the model’s architecture and hyperparameters to ensure
effective learning from the dataset.
Model Evaluation: Evaluating model performance using task-specific metrics to
ensure that the model generalizes well and meets the requirements of the EM tasks.
These steps are crucial for effectively adapting deep learning models to EM tasks, ensuring the models
deliver reliable, task-specific solutions.
To streamline the implementation process of our proposed workflow, we provide the deepem
library, which enables DL
experts to develop their use cases efficiently with minimal overhead. The library simplifies key aspects
of model training by offering built-in support for logging, model checkpointing, early stopping, and
other essential features. For more details, see here.
1. Data
As a DL expert, you will primarily focus on guiding data preparation, which plays a critical role in
the deep learning pipeline. You will provide support in formatting, preprocessing, and structuring the
data to ensure compatibility with the training code. The flexibility of the DeepEM Playground allows for
seamless integration of diverse use cases, with the ability to swap datasets as needed, without altering
the underlying code.
1.1 Data Acquisition
Data acquisition involves gathering raw EM images from different imaging modalities (e.g., TEM, STEM,
SEM). While the EM researchers will manage the collection of raw images, as a DL expert, you will ensure
the dataset meets the model's requirements, potentially suggesting guidelines on balancing and
diversifying the data.
1.2 Data Annotation
Data annotation plays a critical role in model training. We recommend using the data formats supported
by the Computer Vision Annotation Tool (CVAT), a
user-friendly tool designed to simplify the annotation process. You can find a list of supported
annotation formats for CVAT here. To help you get started, we provide a step-by-step guide on using the tool.
You will need to provide a detailed guide on how to annotate the data for your project to ensure that EM
experts are able to exchange the training data if wanted.
1.3 Data Preprocessing
Preprocessing is vital to ensure the data is in the correct format for training. This includes:
Data Reformatting: You should ensure that the data is in formats that are
compatible with EM standards (e.g., .tif, .mrc).
Image Enhancement: You may recommend techniques such as denoising, contrast
adjustment, or augmentation to enhance image quality and improve model performance. If you do so, you
will need to povide specific
guidelines within your use case.
1.4 Data Structuring
The structure of the data is key to enabling flexible use case adaptation. You are encouraged to
organize the data into a clear directory structure for such that EM experts can easily swap out the data
for model development.
We recommend to work with a single file containing all data for training, testing and validation.
Splitting the dataset accordingly should hence be done during runtime in the code.
This can be done using sklearn:
from sklearn.model_selection import train_test_split
# split data into 60% train 20% val 20% test
train, rest = train_test_split(data, test_size=0.4, random_state=42)
val, test = train_test_split(rest, test_size=0.5, random_state=42)
This easy data structure helps ensure that the EM
researchers can easily provide their own training data mitigating the risk of errors. You will need to
provide clear documentation for your use case to ensure consistency and ease of integration.
2. Model Training
Model training involves optimizing the model’s internal parameters (weights) based on the input-output
relationships defined by the training data. This process is guided by a loss function, which quantifies
the error between predicted and actual values. The model is updated iteratively to minimize this error.
Validation is done on a separate dataset to assess the model's ability to generalize, identify issues
such as overfitting, and refine the model's performance.
2.1 Hyperparameter Tuning
Hyperparameter tuning is an essential aspect of model training. We offer an automated search to
simplify this process.
You should define the
default search space within the configs/parameters.json file or modify it as needed. This
file needs to contain tunable and non-tunable parameters with explanations for easy access and
understanding by EM experts. For more details plese see here.
2.2 Training and Validation
We offer a simplisic logging module within the DeepEM playground to continuously monitor training
performance. This logger comes with no additional setup, making it easily accessible by EM experts. Logs
will help EM experts identify potential issues like overfitting, allow them to learn about the process
of model training and inform about improvements for the model.
For each execution of the notebook, the logs are stored in a dedicated directory
(logs/data-current-datetime/). For each training run a subfolder will be created within
this log directory. A subfolder will contain multiple logs which are structured to capture the
following:
Model evaluation determines if the trained model meets the performance criteria and is ready for
deployment. It helps identify areas for improvement or further refinement before using the model in
real-world applications.
3.1 Choose Model
For evaluation, the EM expert will typically select the most recent model, although other models can be
evaluated
by specifying their checkpoint path.
3.2 Evaluation
As DL expert you should choose a set of metrics to assess the model performance, tailored to the
model's objectives. These metrics help you understand the model's strengths and
weaknesses and identify areas for improvement. You will need to detail the provided metrics within the
use
case to ensure that EM experts can interpret the results correctly.
Inference
Inference is the process of using a thoroughly trained and tested deep learning model to make
predictions
on new,
unseen data. It finally allows to use the model to support the analysis of EM data.
1. Define Data
To perform inference with a trained model, you first need to define the data you want the model to
make
predictions on. This could be a specific set of EM data that you wish to analyze. The data can be
provided
as a single file for prediction or as a folder containing multiple files, allowing for automatic
processing of all the included data. This flexibility ensures the model can handle both individual
cases
and larger datasets efficiently.
2. Choose Model
The EM specialist is responsible for selecting a previously trained model for inference. It is
essential
that the model
has been evaluated thoroughly according to the evaluation criteria provided by the DL expert, ensuring
that the evaluation results are promising. Only models with strong performance, as indicated by the
evaluation metrics, should be used for making predictions, ensuring reliable and accurate results.
2. Make Prediction
The model will be used to make predictions on the provided data. However, it's important to remember
that
no trained model is perfect, and human oversight remains essential. The results generated by the model
should always be carefully checked for plausibility to ensure accuracy and reliability.
Inference
During inference, DL experts must ensure that trained deep learning models can be seamlessly applied to
new, unseen EM data. The goal is to provide EM specialists with a reliable and efficient workflow for
generating predictions to support their analysis.
1. Define Data
Our provided deepEMlibrary implements the foundation for
a flexible data loading mechanism that allows EM specialists to provide input
data either as a single file or as a folder containing multiple files. DL experts should implement automatic
processing of all included data while ensuring compatibility with the model’s expected input format.
2. Choose Model
The inference framework should enable EM specialists to select a trained model for prediction. Proper
documentation of model performance and evaluation criteria is essential
for guiding EM specialists in making informed choices.
3. Make Prediction
DL experts are responsible for implementing the inference pipeline, ensuring that predictions can be made
efficiently based on the selected model and input data. The pipeline should be optimized for performance and
include any necessary post-processing steps to produce meaningful results for EM specialists.